
Everything You Need To Know About Computer Vision
- AI/ML
- March 19, 2024
Computer vision is a field of artificial intelligence (AI) and computer science focused on enabling machines to interpret and understand visual information from images or videos. This post provides an extensive overview of computer vision technology, explaining its fundamental concepts, different types of computer vision techniques, and real-life applications of it.
Machines using computer vision to understand and interact with the real world are the future. However, it is something that we have been omnipresent for a while now, from Google Lens to shopping by searching the products similar to the screenshots that you upload in the e-commerce apps. This technology has become a part of some of the daily used applications without most of us knowing about it.
For the CEOs, CTOs, and business analysts who often look at the numbers to see whether the technology hints at a potential future, the Computer Vision market size which is projected to reach US$26.26bn in 2024, is expected to show an annual growth rate (CAGR 2024-2030) of 11.69%, resulting in a market volume of US$50.97bn by 2030.
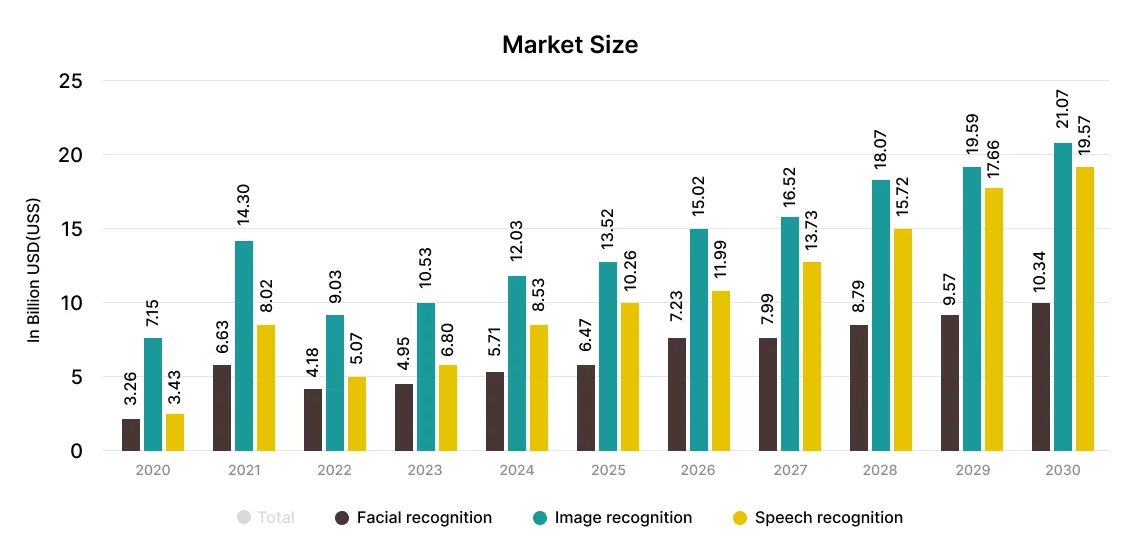
But before collaborating with an AI development company like us to begin your future Computer Vision development projects with this technology, it is crucial to have a fundamental understanding of it. So, let us begin with learning what this technology is.
What is Computer Vision?
It is a field of AI and computer science that enables machines to analyze and comprehend the visual world just like humans do with vision. Basically, it was invented to replicate the human visual system’s ability to interpret, analyze, and understand the visual surroundings.
To do so, the systems have to rely on a combination of techniques which we will learn further to not just recognize but also make decisions based on visual data. This involves the development of algorithms and models that can extract meaningful insights from visual data, such as identifying objects, recognizing patterns, and understanding the spatial relationships between different elements in an image.
How Does Computer Vision Work?
It enables machines to interpret and understand visual information from images or videos, similar to the way humans perceive and process visual stimuli. This process can be broadly categorized as:
- Image acquisition: The process starts with capturing visual data through cameras or other imaging devices and further converting this data into digital format(eg. a set of pixels).
- Pre-processing: This acquired data then undergoes pre-processing(like resizing, normalization, color correction, and more) to enhance their quality and prepare them for analysis.
- Feature extraction: From the pre-processed data, the relevant information or important visual elements are extracted.
- Image recognition: These extracted features are analyzed using Computer Vision algorithms to recognize (identify objects, scenes, or patterns) the content of the images.
- Pattern detection: These algorithms then further analyze the spatial arrangement and relationships between visual elements to identify meaningful patterns or structures in the images.
- Image classification: Based on the recognized patterns or features, computer vision systems classify the images into predefined categories or classes. And assign a label or tag to each image based on its visual content.
- Feature matching: Lastly, the system incorporates learning mechanisms to improve their performance over time.
What is Computer Vision used for?
Depending on the industry it is used in, the uses of Computer Vision vary. Here are some of the real-life applications across various industries and domains:
- Retail: Visual search, Augmented Reality (AR) fitting rooms, inventory management, etc.
- Manufacturing and Industrial Automation: Predictive maintenance, quality control, robotic arms or automated vehicles, and more.
- Autonomous Vehicles: Pedestrian detection, gesture recognition, etc.
- Healthcare: Medical imaging, surgical assistance
- Banking and Finance: Fraud detection, facial recognition, surveillance analysis, and more.
To explore more about these applications in detail, explore our blog on the applications of Computer Vision.
Types of Computer Vision Techniques
Computer vision techniques are a wide array of methods and algorithms aimed at extracting meaningful information from images or videos. Here are some common types of computer vision techniques:
Image Classification/Recognition
This technique is used to provide computer systems with the ability to classify/accurately predict the class/category of any given image.
But for computer systems to recognize objects just as humans is quite impossible without undergoing extensive training using large datasets that contain object representations/labeled images at various angles, perspectives, and contexts. This task is easily done by assigning single labels or tags upon analyzing the entire image as a whole for categorizing images into predefined classes or categories. The business can also consider using synthetic data over real data for better model training purposes.
Further, these labeled images serve as reference points during the training phase, allowing the computer system to learn and correlate visual features with specific object classes and make educated assumptions based on them.
For example, for a given photo of a cat, the computer will classify it as a “cat.”
Object Recognition/Detection
Take image recognition a step further, object recognition or detection, if the image or video contains multiple objects say for example both cat and dog then with object recognition the computer system would label each object detected in the image or video individually.
The best real-time example of it is the object recognition of an autonomous car. As the autonomous car navigates through the streets, its computer vision system continuously analyzes the live video feed from its cameras to identify and classify various objects in its surroundings, such as pedestrians, bicycles, cars, and even animals like cats and dogs, all sharing the same visual space.
Object Tracking
Unlike object recognition, which identifies objects in a single frame, object tracking focuses on maintaining the identity of objects over time as they move within a video. This enables computers to analyze and understand the motion and behavior of objects in real-time video streams. This facilitates object localization, motion analysis, behavior prediction, and more.
Imagine a surveillance system monitoring a parking lot. Using object tracking, the system can detect and track vehicles as they enter and exit the parking area. Initially, the system identifies each vehicle in the first frame of the video and assigns a unique identifier to them.
As the video progresses, the system continuously tracks the movement of each vehicle, updating their positions in subsequent frames. This allows the system to monitor the trajectory of vehicles, detect any suspicious behavior, and provide real-time alerts to security personnel if needed.
Image Segmentation
This involves partitioning an image into multiple meaningful and semantically coherent regions or segments based on similar visual characteristics such as color, texture, or intensity.
It plays a crucial role in medical imaging for identifying and delineating different anatomical structures and abnormalities within the body in MRI or CT scans. Specifically, in tumor detection, image segmentation techniques are used to highlight regions of interest corresponding to potential tumors.
There are several techniques used for image segmentation, including:
- Thresholding Segmentation: Dividing the image into regions based on pixel intensity values relative to a specified threshold.
- Edge-Based Segmentation: Identify and delineate the boundaries or edges of objects within an image.
- Region-Based Segmentation: This approach involves grouping together pixels with similar properties, such as color, texture, or intensity, into coherent regions.
- Watershed Segmentation: Segmenting objects in an image based on gradients or intensity variations.
- Clustering-Based Segmentation: Partition an image into segments or regions based on the similarity of pixel properties.
To streamline image segmentation, the best foot forward is to leverage ML development services from a company with expertise in working on similar projects giving your project a competitive edge.
Keypoint/Landmark Detection
As the name suggests, this technique involves identifying specific points or landmarks within an image with visual significance, like edges, corners, high-contrast regions, facial landmarks, and more. These detected key points serve as reference markers for machines to analyze real-time content. This technique recognizes emotion, pose, fashion landmarks, and more.
Depth Perception
It enables the computer systems to understand the depth or distance of the object from a reference point with the image. Basically, it enables these systems to see the objects in 3-dimensional (3D) representation by judging the relative distance of the objects. It is achieved by the combined capabilities of depth sensors, monocular depth estimation, Stereo vision, Time-of-Flight (ToF) Cameras, machine learning algorithms, and more.
It is crucial in real-life applications like autonomous vehicles. This technique enables these vehicles to navigate safely through their environment by making informed decisions based on the distance estimation of objects such as other vehicles, pedestrians, and obstacles on the road.
3D Reconstruction
It refers to creating a 3D representation or model of an object or scene from a two-dimensional (2D) or series of images. This can be best explained as a digital model of the historical building created by an architectural firm either for renovation or preservation from photographers or drone images.

Content-based Image Retrieval (CBIR)
Just as to find the text based on the term mentioned in the search bar, in this technique, an image is used as a query rather than queries or metadata to fetch similar images from the database by comparing it with the query image. This eliminates the need to provide keywords or descriptive tags when finding images. These images are indexed and retrieved based on their visual features, such as color, texture, shape, and spatial layout.
One of the simplest examples of this is Google Images. This technique is further implemented in various eCommerce sites to facilitate users with an image-based search experience to look for desired products. Some of its wide range of applications also includes satellite image analysis, surveillance systems, digital asset management, and more. If you have an idea similar to Google Lens and need a team with technical capabilities to bring it to life, hire ML developers from us to augment your existing team.
Video Motion Analysis
Video motion analysis in computer vision refers to the process of analyzing and understanding the movement and trajectory of an object within a sequence of video frames.
This can be best demonstrated by its application of sports analysis. From analyzing player’s performance metrics like sprint speed, acceleration, and more to skill assessments like dribbling, passing accuracy, ball control, and shot placement.
Feature Matching
It is a feature of identifying the corresponding features or key points like points, edges, corners, or descriptors between multiple images. These features represent distinct and recognizable patterns or relevant pieces of information in the images.
In industrial automation systems, for example, feature matching facilitates quality control, defect detection, and object recognition. One of its most common use cases is to align and stitch together multiple overlapping images to create seamless panoramas.

Lead Innovation with MindInventory’s Computer Vision Solutions
With MindInventory’s computer vision software development services, you’re empowered to harness the full potential of computer vision technology and stay ahead in today’s rapidly evolving digital landscape. Hire AI developers who specialize in delivering innovative solutions tailored to your specific needs, leveraging advanced algorithms, machine learning, and image processing techniques.
Whether you’re exploring real-time processing, scalable architectures, or algorithmic optimization, we’re here to help you lead innovation and extend your business reach globally. Talk to our experts today to discuss how we can assist you in your future computer vision projects.












